Production-Grade AI Code: Why Process Beats the Model

What separates production-grade AI code from vibe-coded slop isn't the model. It's the engineering process around it. Spend ten minutes on r/vibecoding and you'll see the same story on repeat. Someone ships a full stack app in a weekend, posts the demo, gets the upvotes. Two weeks later they're back: three copies of the auth flow, API keys in the frontend, a database with no migrations, and a folder structure only the model that wrote it could navigate.
The common diagnosis is that AI writes bad code. But think about how a real engineering team works. No code reaches production without architecture standards, CI, code review, and branch protection. A junior engineer doesn't get to wire the frontend directly to the database, skip migrations, or commit API keys to the repo. The team's process prevents it.
Why would AI be any different?
The biggest tell of slop isn't the variable names or the stock photo landing page. It's the architecture, or the complete absence of it. At Appifex, we built the engineering process that was missing.
Architecture by default
Every app generated on Appifex inherits a production scaffold before the AI writes a single line of business logic.
On the backend, that means FastAPI with SQLAlchemy and Alembic. Five layers (Routers, Dependencies, Services, Models, Schemas), versioned migrations, one PostgreSQL schema per app, Pydantic validation on every request and response, dependency injection for DB sessions and auth, and structured JSON logging with request ID propagation.
On the web frontend: React with TypeScript in strict mode and Tailwind with shadcn/ui. Strict mode catches type errors at build time. A design token system and preconfigured component library mean the AI extends existing components instead of reinventing buttons from scratch.
On mobile: React Native with Expo, the same TypeScript discipline, file system routing via Expo Router, layered error capture with Sentry, and an OTA update system for instant previews on real devices.
The AI fills in business logic on a scaffold that already has proper separation, migrations, validation, and logging. It can't create a flat file database or wire the frontend directly to PostgreSQL because the architecture is already there and the AI operates within it.
Enforced patterns and data flow
The AI agent doesn't just get a prompt saying "build a todo app." It operates under architectural rules enforced by the system prompt and a middleware layer that gates what tools are available and what files can be written.
For fullstack apps, backend comes first: models, schemas, routes, schema push, seed data. Then frontend derives from it: TypeScript types matching Pydantic models, API client, components, pages. The backend defines the contract, the frontend adapts. One direction, never the other way. API base URLs come from environment variables, never hardcoded.
This is how real teams work. The AI follows the same discipline because the system enforces it.
Secret management that actually works
One of the most common failures in vibe coded projects: API keys sitting in frontend code.
All credentials live in an encrypted vault, not .env files committed to git. They're decrypted only at injection time. The build system enforces prefix rules per platform: web builds only receive VITE_* variables, mobile only EXPO_PUBLIC_*, backend gets the server side secrets. Third party API calls route through a backend gateway proxy, and the QA pipeline scans frontend bundles for direct API domain references.
You can't accidentally expose a secret. Storage, injection, and verification each catch it independently.
The QA pipeline
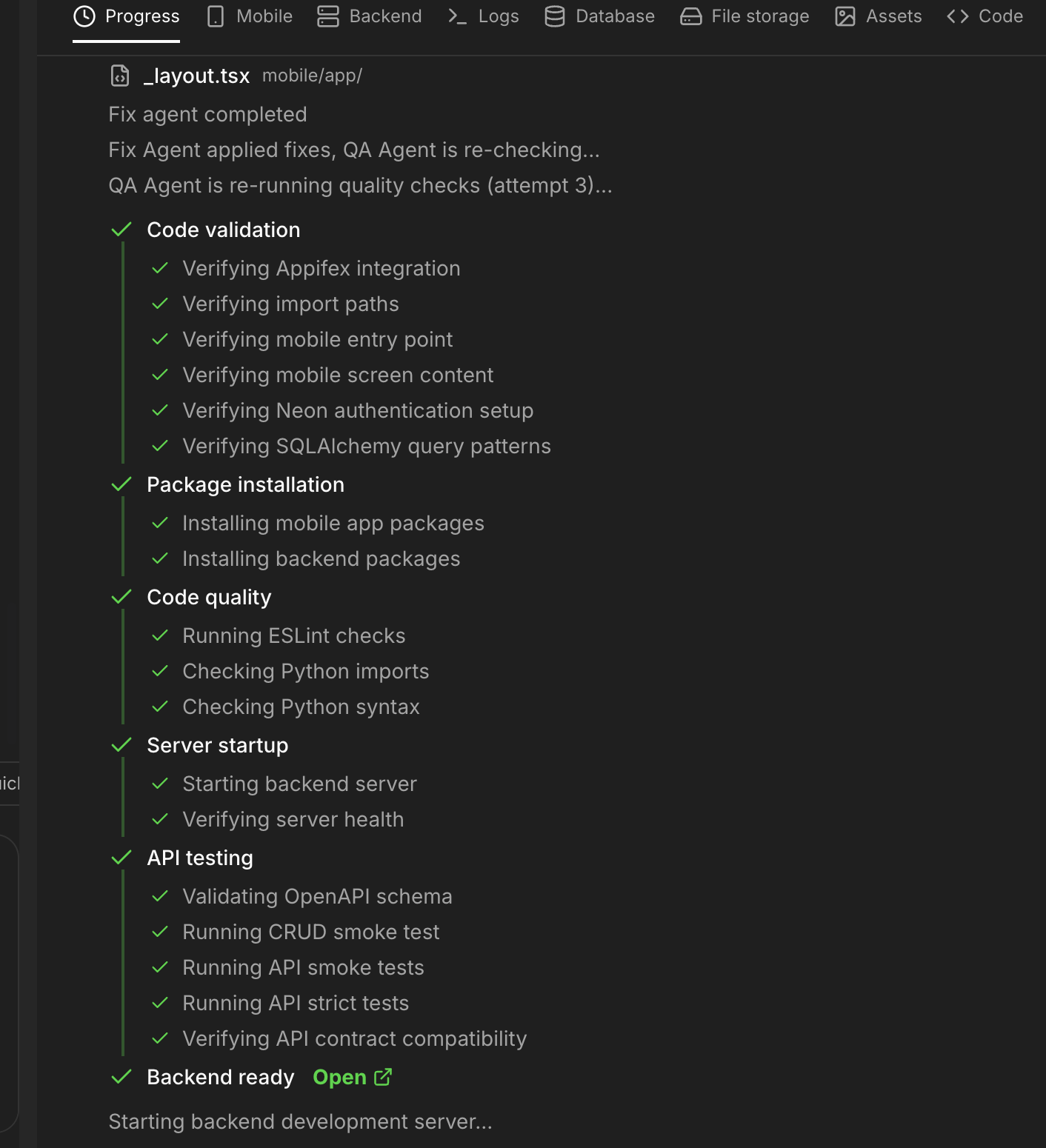
After code is generated, a six stage CI pipeline runs automatically inside a real cloud sandbox: code pattern analysis at the AST level (not regex), dependency installation, linting, build, server startup verification, and endpoint testing. Stages are ordered from cheapest to most expensive, and a blocking failure halts the pipeline early.
This isn't "check if it compiles." It runs the actual app, hits real endpoints, and verifies that frontend API calls match backend routes. The same thing a CI pipeline does at any serious company, automated into every generation cycle.
When CI fails: the fix agent
When the QA pipeline catches issues, a fix agent kicks in automatically, up to three retry cycles.
The fix agent has real debugging tools: structured logs, database diagnostics, stack traces, server health checks. It follows the same process a senior engineer would: read the logs, find the root cause, fix one thing at a time. Fifteen endpoints returning 404 is one server startup failure, not fifteen bugs. Common patterns like import errors get fixed deterministically without invoking an LLM at all. And a circuit breaker stops the loop if the same error repeats, so we're never burning tokens going in circles.
Code review and branch isolation
In a real team, no code reaches production without review. We apply the same flow to generated code.
Every generation session creates its own git branch. A GitHub PR opens automatically with the user's prompt and an AI summary in the description. A review agent analyzes the diff for bugs, security issues, best practices, and performance, then applies minimal targeted fixes directly to the PR branch.
Branch, CI, review, merge. The code that reaches main has been generated on a production scaffold, passed the QA pipeline, been repaired if needed, and reviewed before merging.
Process is the product
When the model has existing code, a proper backend, and clear architecture to reference, it hallucinates way less because it's grounded in something concrete.
The difference between professional software and vibe coded slop isn't which model you pick. GPT-5, Claude, Gemini: they all produce roughly similar code when given a blank canvas and a one line prompt. The difference is the process around them. Architecture standards instead of blank files. Enforced layer separation instead of spaghetti. Encrypted secrets instead of hardcoded keys. A real CI pipeline instead of "it works on my machine." Automated repair instead of manual debugging. Code review instead of shipping the first draft.
Real engineering teams have spent decades building these practices. We think generated code deserves the same rigor.
For more on how the error recovery pipeline works in detail, read self-healing agents that give your time back. To see how this architecture enables real mobile apps, see how Appifex closes the mobile app gap. And for the full story on code ownership, see what Appifex does that other builders won't.